먼저 개인적인 프로젝트로 인하여 여러 가지를 하고 싶음에도 불구하고 음성인식에 관해 알아보고 실제로 인공지능 비서를 만들어 보려고 합니다 참고로 저도 배우는 단계에서 여러 유튜브의 강의들과 블로그 및 논문 등을 찾아보면서 할 것인데요 Tf2.0같은 것들도 제 프로젝트가 모두 끝난 후 진행할 예정입니다. 하지만 가끔씩 너무 힘들면 기분전환 삼아 올리는 것들을 멈추었던 것들을 조금씩 올릴 것 같습니다. 아 그리고 저는 누구를 기준을 맞추어서 가냐면 인공지능을 이제 막 공부하기 시작한 사람 초점으로 맞추려고 합니다. 그래서 어려운 파트는 과감하게 편집하거나 영상 참고 바란 다는 글을 대부분 남기게 될 것 같네요
항상 저의 블로그를 보실 때 저는 아직 대학원을 들어가서 전문적으로 배우는 사람이 아닙니다 물론 대학원을 목표로 삼고 달려가고 있는 사람이지만 누구에게 제대로 배우고 한 것이 아니라는 점 유의해주세요 그리고 제가 지금 진행 중인 프로젝트 같은 것들은 알려드려야 참고하실 때 좋을 것 같아서 알려드리자면 제가 진행 중인 프로젝트는
1. 유니티로 시뮬레이터만들기(강화학습을 위해)
2. 타코트론을 이용한 AI비서 만들기
3. 강화학습
4. 유니티로 게임 만들기
A. 일반 게임
(참고로 저는 게임 개발이 처음입니다)
5. 데이터 분석
6. 캐글
이렇게 총 6가지 정도 될 것 같습니다. 참고해주세요
자 이렇게 해서 오늘은 타코 트론을 이해하기 위해 먼저 그 타코 트론에 들어가는 Attention에 대해 집중적으로 공부하려고 합니다. 먼저 타코 트론이 어떻게 돌아가는지 순서도를 보시죠
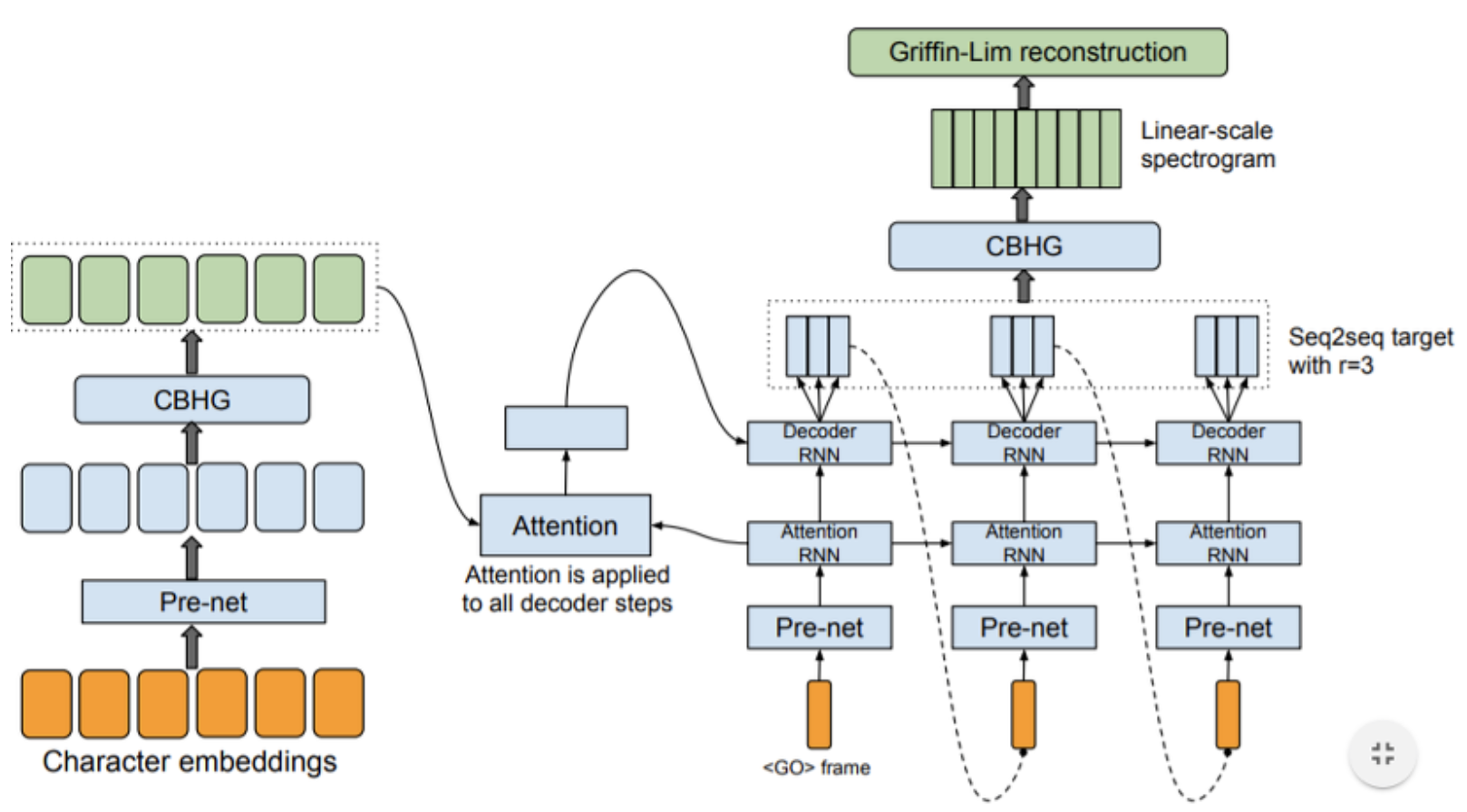
이렇게 타코 트론은 돌아간다고 합니다 이 그림은 참고로 말씀드리자면 구글에서 Tacotron을 검색하면 똑같은 사진을 구하실 수 있습니다. 그림에 대해서 아직까지는 잘 모르셔도 좋습니다! 당연히 처음 보는데 이해가 안 되는 것이 당연한 일이죠! 아 그리고 저는 Tactron1을 먼저 한 후 나중에 인공지능 비서를 완성한 후 나중에 Tacotron2를 다루어보도록 하겠습니다.
논문 참고는 Attention Is All You Need라고 하고요
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
그 외 여러 가지 찾아봤습니다.....(대표적으로 서운산 미디어 센터의
Attention과 Transformer의 직관적 이해 (18-1)
https://www.youtube.com/watch?v=-kY4Yc8qfho
라는 유튜브 강의를 참고했습니다)
자 Attention에 대해 본격적으로 알아보도록 하겠습니다.
우선 상당히 Attention을 이해하기 어렵다는 점을 먼저 알려드리고 싶습니다.....
Attention 같은 경우는 RNN CNN을 안 쓴다고 합니다. 저 같은 경우 RNN이나 CNN은 친숙하지만 Attention의 이론을 처음 들었을 때 무엇인가가 새로웠는데요. 기존 Attenstion을 사용하기 전 sequence data를 처리할 때 여러 문제점이 존재하였습니다. 간단하게 설명하자면 기존 classic solution은 RNN을 이용하는데 짧은 문장 같은 경우는 문제가 없지만
long-term dependency(장기 의존성)에 취약하다는 단점이 있었습니다. 무슨 말인지 모르실 수 있습니다. 저는 그러니까 컴퓨터의 메모리 한계까지 오는 데이터들이 존재할 수 있습니다. 고로 이 데이터들은 한 번에 순서를 기억하여 학습시킬 수 없게 될 것입니다. 그렇기에 여기서 많은 문제점이 나타날 수 있는데 대표적으로 데이터의 순서를 모른다거나 또는 데이터가 유실될 수 있는 상황에 처하게 돼서 만일 내가 지금 메모리에 있는 데이터가 책이라는 한 단어일 때 컴퓨터는 이게 동화책을 말하는 것인지 전공책을 말하는 것인지 알 수 없게 된다는 뜻도 있는 거 같습니다. 옆에 물어볼 사람이 없어서 나 스스로가 잘 이해한 건지 모르겠습니다만 이런 느낌 같은 거다라고 생각해주세요(혹시 제가 잘 못 이해했다면 댓글로 알려주세요 즉시 바꾸겠습니다!)
일단 이해를 못하셨다고 하면 기존 처리방식에서는 많은 문제점이 많았다고 생각해주시고 그래서 Attenstion이라는 개념이 나왔고 하지만 Attention도 잘 처리는 해주지만 여전히 문제 속도가 느려지거나 여러 가지 문제가 발생\했습니다. 그래서 이러한 문제를 해결해 주기 위하여 Reducing Sequential Computiation(순차적 계산 감소)라는 개념을 사용하려고 했다고 합니다.(이 내용은 Attention을 이해하는데 그렇게 중요한 내용같지는 않아서 간단하게 말했습니다 하지만 개념이니 알고 넘어가는 편이 좋을 것 같습니다 아직 많이 잘 모르잖아요? ㅎㅎ)하고 이제 Attention을 설명하기 위해 Encoder와 Decoder를 설명하고 오늘은 여기까지 할려고 하는데요 아 그리고 저희는 Attention개념은 먼저 Transformer network 중심으로 다룰 거고 아마 다음 올라가는 것은 Tacotron과 직접적으로 연관된 내용일 겁니다 지금은 Attenion을 중심으로 보는 거고요


첫 번째 그림 같은 경우는 Encoder와 Decoder에 Transformer network로 표현한 거라고 생각하시면 되겠습니다 Transformer network는 쉽게 생각하시면 번역기라고 생각하시면 편하고요 그 번역기 내부가 어떻게 돌아간다라는 UML이라고 생각하시면 편할 듯합니다. 두번째 그림 같은 경우는 좀 더 간단하게 설명한 그림입니다. 값이 들어가면 Endcoder에서 처리를 해서 Decoder로 보내주고 Decoder에서 정리를 한 후 보여준다라는 개념을 잘 나타낸 그림 같습니다. 하지만 만약 두번째 그림처럼 Encoder가 한 개이고 Decoder가 한 개 이면 무슨 일이 벌어질까요? 만약 여러분들이 인공지능 공부를 CNN이나 그런 것들을 먼저 해보았다면 답을 아실 듯 합니다. 네 바로 정확성이 떨어진다는 단점이 생길 수 있습니다. 하지만 첫 번째 그림의 화살표 순서대로 해준다면? Encoder가 한 개인 것보다 더 정확성이 높아지게 될 것입니다 그렇다면 Encoder를 아주 많이 만들면 정확성이 100에 가까워지지 않을까라는 생각도 해볼 수 있습니다. 이 것 또한 CNN과 마찬가지로 일정량에 학습을 하면 정확도가 잘 올라가지 않는 구간이 있습니다. Encoder 또한 마찬가지이고 Encoder가 많아지게 된다면 속도도 Encoder의 양만큼 더 걸리게 될 것입니다.
Encoder의 개수는 흔히 7개 정도가 적당하다고 합니다. Encoder만 설명하셔서 Decoder에 대해서 궁금하실까 봐 설명을 드리자면 Transformer network기준으로 한국어로 "안녕하세요 제 이름은 whitewatch입니다"를 분석해서 영어로 바꿔준다고 치면 Encoder에서는 한국어를 분석하여 영어로 바꾸어주고 Decoder에서는 그 영어로 바꾼 것들을 영어 문법에 맞춰서 다시 재번역을 한 후 유저한테 보여준다고 생각하신다면 Encoder, Decoder에 더 빠르게 이해하실 수 있을 겁니다.
앞에서는 간단하게 설명했는데 이해하셨는지 모르겠네요 이제 Encoder Layer하나하나 깊게 들어가서 보려고 하는데요.... 의도되지 않게 그림을 막 넣는다고 넣는 건데 그림보다 글자가 더 많네요 최대한 이해를 쉽게 하려고 했는데 처음 보는데 머리가 많이 아프시단 건 당연한 거고요 이 뒤부터는 설명은 할 것이지만 듣고 싶지 않다면 추후에 듣는 방법도 좋은 방법입니다.
자 이제 Encoder Layer에 대해 알아보도록 하죠 Encoder내부에는 Self Attention + FFN(FeedForward Network)가 안에 존재한 상태이고요 이 상태로 똑같은 구조를 가진 Encoder가 여러 개가 있어서 열심히 돌아간다는 거고 여기서 Self Attention이 있고

제가 왜 매듭을 보여드렸냐면 음 본론부터 말씀드리면 우리는 값 두 개를 가지고 와서 곱하거나 합칠 것이고 이 짓이 매듭을 묶는 것과 비슷하다고 유튜브 영상에서 설명을 하십니다. 해서 값이 크다면 잘 학습이 된 것으로 판단합니다. 무슨 말인지 모르시겠다면 자세히 알아보도록 하죠
결국은 Encoder가 있고 Decoder가 있으면 두 개가 잘 엮어서 값이 나가야만 합니다.
흠 제가 생각했을 때 이 부분은 그림 하나로 본론만 말하는 편이 좋을 듯해서 만약 깊숙이 알고 싶다면 앞에 링크를 걸어둔 영상을 보시는 걸 추천드립니다.

네 self attention이 돌아가는 UML인데요 여기서 Q와 K를 곱하고(두 수가 크기가 같으면 높은 값이 나옴) 거기에 V를 곱하여 V로 인하여 평준화되어 비교하기 쉬운 형태로 바뀌면서 얼마나 잘 학습이 되었는가를 비교할 수 있게 됩니다.
급하게 결론을 내버린 것 같은 경향이 있습니다만 더 알고 싶다는 분들은 영상 참고 바랍니다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 타코트론 제 3 장 (2) | 2020.01.21 |
|---|---|
| Tacotron 제 2 장 (0) | 2020.01.18 |
| Tacotron제 1 장 (1) | 2019.12.27 |
| Tacotron에 관해서.... (0) | 2019.08.22 |


